Method
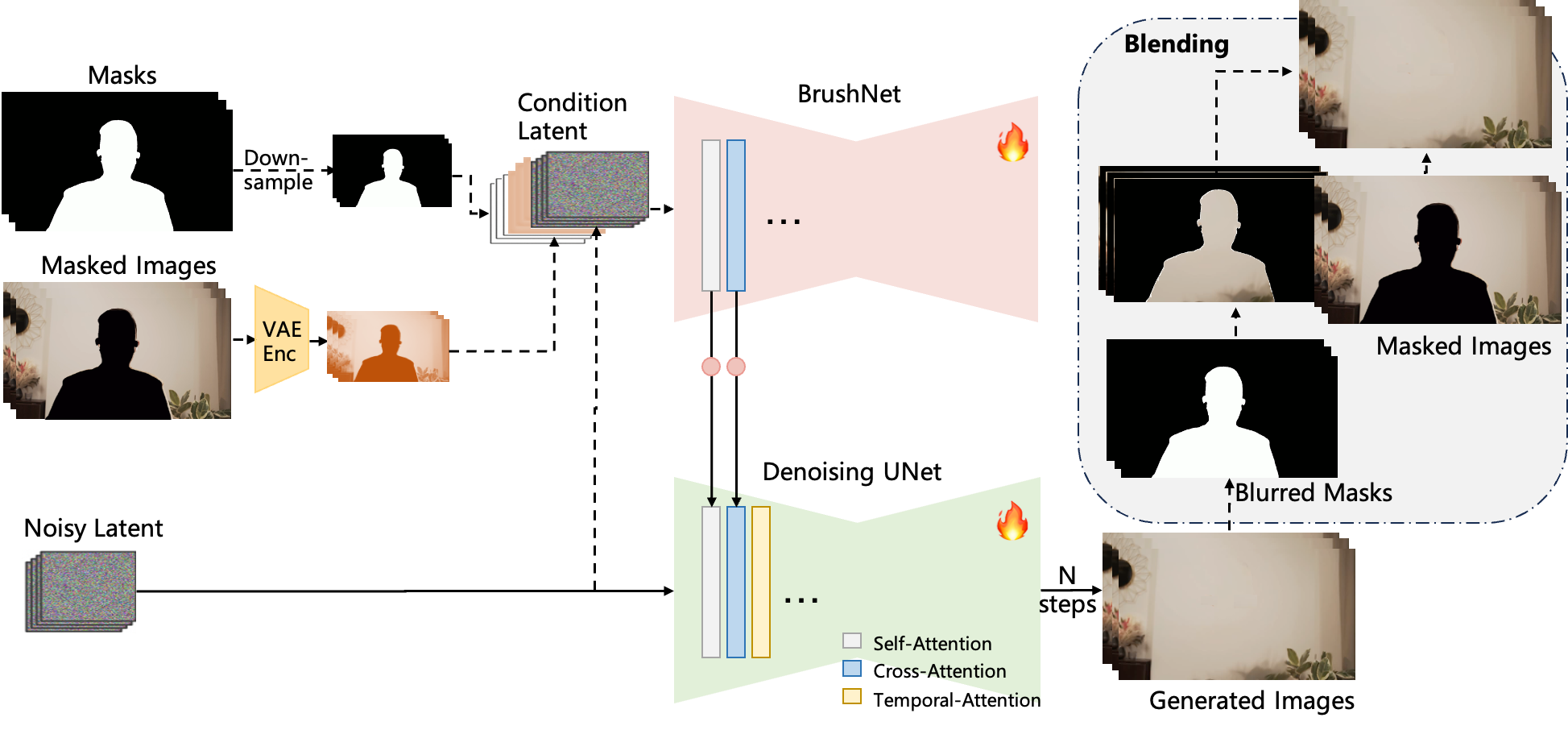
Overview of the proposed video inpainting model DiffuEraser, based on Stable Diffusion. The main denoising UNet performs the denoising process to generate the final output. The BrushNet branch extracts features from masked images, which are added to the main denoising UNet layer by layer after a zero convolution block. Temporal attention is incorporated after self-attention and cross-attention to improve temporal consistency.
We incorporate `prior` information to provide initialization and weak conditioning, which helps mitigate noisy artifacts and suppress hallucinations. Additionally, to improve temporal consistency during long-sequence inference, we expand the `temporal receptive fields` of both the prior model and DiffuEraser, and further enhance consistency by leveraging the temporal smoothing capabilities of Video Diffusion Models. Please read the paper for details.